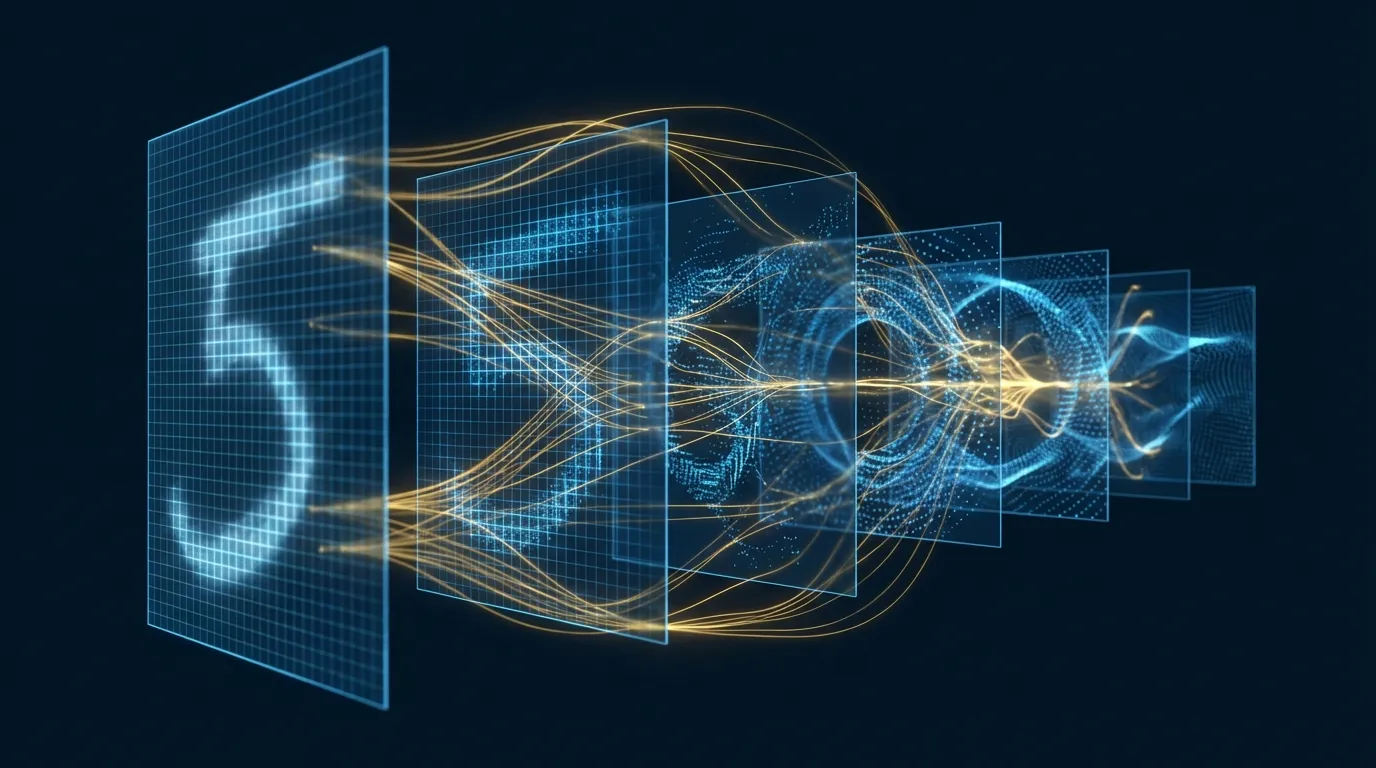
- 本文以直覺比喻 + 完整程式碼的方式,從零實作一個 MNIST 手寫數字擴散模型——從前向加噪到反向去噪,9 個步驟全部走過一遍
- 核心架構僅 2.17M 參數的輕量 U-Net,在 RTX 4090 上訓練 3.4 分鐘即可從純噪聲生成清晰的手寫數字
- 完整實作條件生成與 Classifier-Free Guidance(CFG)[2]——輸入數字標籤即可指定生成 0~9,並比較不同 CFG 強度的效果
- 附可下載 Jupyter Notebook,支援 Google Colab 一鍵運行,無需本地 GPU 即可完成全部實驗
擴散模型的大比喻:修復照片的專家
在深入程式碼之前,先用一個簡單的比喻理解擴散模型的完整邏輯:
想像你要訓練一個照片修復師:
- 拿一張清晰照片 → 灑沙子蓋住它(加噪聲)
- 讓修復師看被沙子蓋住的照片,學會「掃沙子」(去噪)
- 學會後,隨便給一堆沙子(純噪聲),修復師也能「掃」出一張真實的照片
這就是擴散模型的核心[1]!接下來我們用 9 個步驟完整實現它。
Step 1:環境設定 & 載入 MNIST
1.1 匯入套件 & 偵測 GPU
第一步是確認工作環境——把所有工具擺到桌上(import),然後確認工作台是「一般桌子(CPU)」還是「超級快的電動工作台(GPU)」。
import math, torch, torchvision
import matplotlib.pyplot as plt
from torchvision import transforms
from torch.utils.data import DataLoader
from torch.optim import Adam
import torch.nn.functional as F
from torch import nn
from tqdm import tqdm
device = 'cuda' if torch.cuda.is_available() else 'cpu'1.2 超參數設定
決定照片大小、每次看幾張、灑沙子分幾層、練習幾輪。這些是訓練的「計畫表」:
| 參數 | 值 | 意義 |
|---|---|---|
img_size | 28 | MNIST 圖片大小 28×28 像素 |
batch_size | 128 | 每次練習看 128 張圖 |
num_timesteps | 1000 | 灑沙子分 1000 層(T=1000) |
epochs | 10 | 練習 10 輪 |
lr | 0.001 | 學習速度 |
1.3 載入 MNIST 資料集
去圖書館搬 60,000 張手寫數字照片回來,裝進 469 個箱子(batch),每箱 128 張。

圖 1 — MNIST 手寫數字原始圖片,黑底白字,每張 28×28 像素
Step 2:理解前向擴散過程(加噪聲)
前向擴散的直覺:拿一張清晰照片,第 1 次灑一點沙(幾乎看不出來),第 100 次灑更多,第 1000 次灑到完全看不到原圖。數學上:
xt = √ᾱt · x0 + √(1−ᾱt) · ε
ᾱt = 原圖保留比例 | ε = 隨機噪聲
2.1 ᾱt 衰減曲線 —「灑沙子計畫表」
想像你拿一杯清水(原圖),每一步加一滴墨水(噪聲):
- t=1(最左邊): 剛加一滴,水還是透明的(ᾱ=0.9999,幾乎原圖)
- t=500(中間): 加了 500 滴,水變灰了(ᾱ=0.08,只剩 8% 原圖)
- t=1000(最右邊): 全黑了(ᾱ≈0,完全是噪聲)
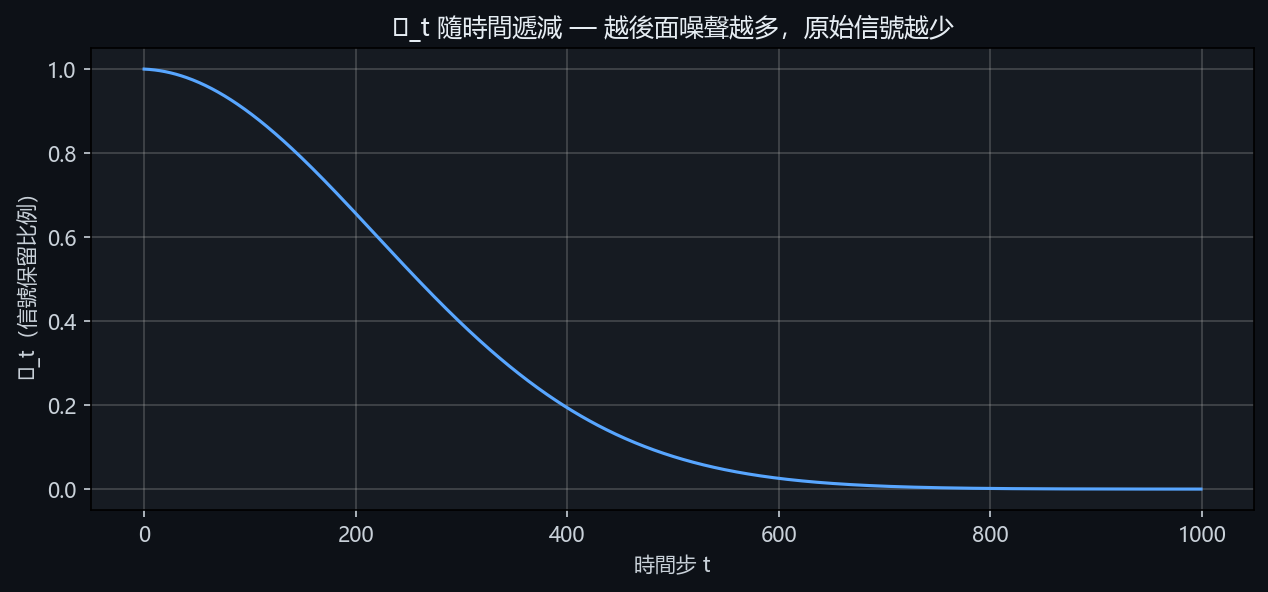
圖 2 — ᾱt 隨時間遞減曲線,從幾乎保留原圖到完全變成噪聲
2.2 加噪示範
擴散模型要學的事就是:反向走這條路!從最右邊的雜訊,一步步還原出最左邊的清晰數字。

圖 3 — 前向擴散過程:原圖逐漸變成純噪聲
Step 3:位置編碼(Positional Encoding)
修復師在掃沙子時,需要知道「現在是第幾層」。剛開始(t=1000)沙子最多,需要大力掃;快結束(t=1)沙子很少,只需輕輕拂。位置編碼用 sin/cos 波形[4],讓每個時間步 t 都有自己獨特的「指紋」:
- 低維度(左邊)變化快 → 區分相鄰的 t(如 100 和 101)
- 高維度(右邊)變化慢 → 區分差距大的 t(如 1 和 1000)

圖 4 — 不同時間步的正弦位置編碼,每個 t 都有獨特的「指紋」
Step 4:U-Net 模型架構
U-Net[3] 是修復師的「大腦」——結構像一個 U 形漏斗:左半邊壓縮圖片(從遠到近觀察),底部是核心理解,右半邊再放大回原尺寸。Skip connections 像是「備忘錄」,確保放大時不會丟失細節。
輸入(1,28,28) → [Down1: 64ch] → MaxPool → [Down2: 128ch] → MaxPool
↓ skip ↓ skip
[Bot: 256ch]
↑ skip ↑ skip
輸出(1,28,28) ← [Up1: 64ch] ← Upsample ← [Up2: 128ch] ← Upsample關鍵設計:
- Skip connections:encoder 直接連到 decoder,保留細節(像備忘錄)
- 時間步嵌入:每個 ConvBlock 都接收時間步資訊,知道「現在該掃多少沙子」
- 輸入:一張有噪聲的圖 + 「現在是第幾步」
- 輸出:模型猜測的噪聲 —「我猜你加了這些沙子」
修復師的大腦有 2,167,784 個參數(2.17M),但現在還是空白的。接下來要「上課」教他。
Step 5:Diffuser 類別
Diffuser 是修復師的「工作手冊」,裡面寫了三個標準流程:
add_noise— 如何灑沙子(前向過程)denoise— 如何掃一層沙子(反向一步)sample— 完整的從頭到尾掃 1000 層沙子(生成圖片)
Step 6:訓練擴散模型
訓練過程就像上課考試[1],反覆做同一件事:
- 老師拿一張清晰照片(x₀)
- 隨機灑某個量的沙子上去(得到 xt)
- 學生看被沙子蓋住的照片,猜:「我覺得你灑了這些沙子」
- 老師對答案:「你猜的沙子 vs 實際灑的沙子,差了多少?」(MSE Loss)
- 學生根據差距調整自己的猜測能力
重複 10 輪(epoch),每輪看完 60,000 張照片。練習越多,猜得越準!
6.1 訓練結果(修復師的成績單)
| 輪次 | Loss(越低越好) | 比喻 |
|---|---|---|
| Epoch 1 | 0.046950 | 剛上課,猜得很差 |
| Epoch 2 | 0.027240 | 開始有感覺了 |
| Epoch 5 | 0.021274 | 越來越熟練 |
| Epoch 8 | 0.019269 | 快畢業了 |
| Epoch 10 | 0.018689 | 畢業!猜噪聲很準 |
在 RTX 4090 上,整個訓練只花了 203.2 秒(3.4 分鐘)。在 Google Colab 的免費 T4 GPU 上大約需要 10-15 分鐘。
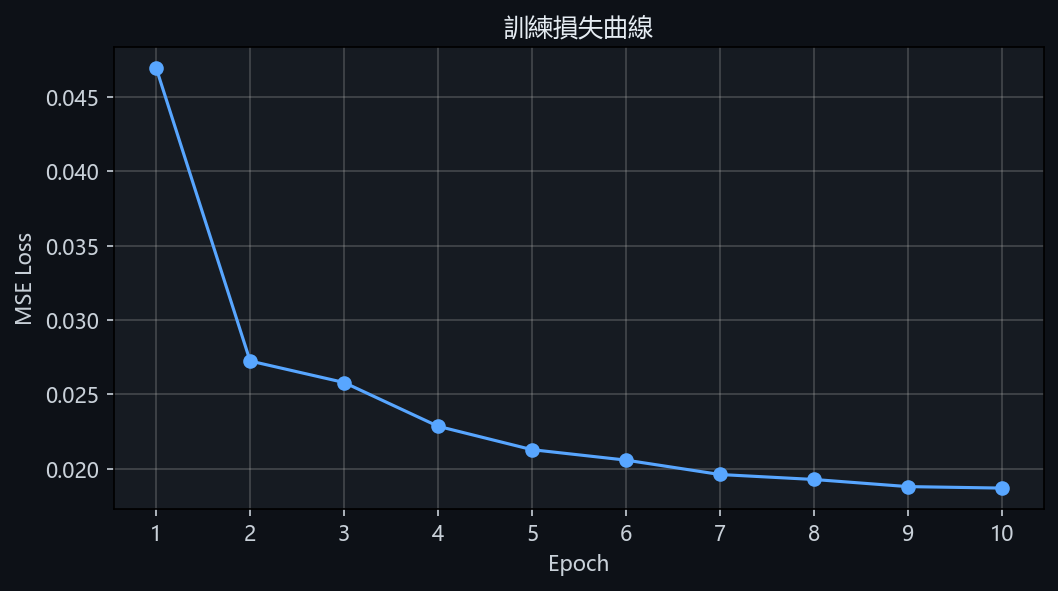
圖 5 — 訓練損失曲線,Loss 穩定下降代表模型逐漸學會預測噪聲
Step 7:生成圖片!
畢業考試!給修復師一堆純沙子(純噪聲),看他能不能從零「掃」出一張真實的手寫數字:
- 從純噪聲 xT ~ N(0, I) 開始 — 一堆隨機的沙子
- 用模型預測噪聲,去除一點點
- 重複 1000 步
- 最終得到一張清晰的手寫數字圖片!
20 張手寫數字成功從純噪聲中生成,全部沒有參考任何原圖,耗時僅 6 秒:

圖 6 — 擴散模型生成的手寫數字(全部從純噪聲生成!)
Step 8:觀察去噪過程
用慢鏡頭拍下修復師掃沙子的過程,從純沙子到最終清晰的數字:
- t=1000(最左邊):純沙子,什麼都看不到
- t=900~700:開始隱約出現形狀,像在霧裡看東西
- t=600~400:形狀越來越清楚,可以看出是某個數字了
- t=300~100:數字已經很明顯
- t=50~0(最右邊):完全清晰的手寫數字

圖 7 — 反向去噪過程:從純噪聲一步步還原出清晰的手寫數字
Step 9:條件生成 — 指定要生成哪個數字!
之前的修復師只會隨機掃出數字,無法指定。現在訓練升級版——你跟他說「我要 7」,他就掃出 7。做法是在灑沙子時附一張小紙條寫「這是數字 7」:
- 把數字標籤(0~9)用
nn.Embedding轉成向量,和時間步向量相加後餵給 U-Net - 訓練時有 10% 的機率隨機丟棄標籤(CFG 技巧[2])——讓修復師同時學會「有提示」和「沒提示」兩種情況
- 比無條件模型只多了 1,100 個參數(class_embed),非常輕量

圖 8 — 條件生成:指定生成 0~9(CFG scale=3.0)
9.1 Classifier-Free Guidance(CFG)強度比較
CFG scale 就像點菜的「語氣」——越大聲,修復師就越聽話[2]:
| CFG Scale | 比喻 | 效果 |
|---|---|---|
| scale = 1.0 | 輕聲說「請給我 3」 | 大概是 3,但偶爾跑偏——多樣性高,不太穩定 |
| scale = 3.0 | 正常說「我要 3」 | 穩穩的 3,風格有變化——品質和多樣性的最佳平衡 |
| scale = 7.0 | 大聲喊「一定要 3!」 | 非常清晰的 3,但每張都很像——品質最高但多樣性最低 |

圖 9 — CFG 強度比較:scale 越大越「聽話」,但多樣性越低
總結:9 步走完擴散模型全流程
| 步驟 | 做了什麼 | 比喻 |
|---|---|---|
| Step 1 | 環境設定 & 載入 MNIST | 開店準備、搬教材 |
| Step 2 | 前向擴散(加噪聲) | 灑沙子蓋住照片 |
| Step 3 | 位置編碼 | 每一步的「身份證」 |
| Step 4 | 建 U-Net 模型 | 修復師的大腦 |
| Step 5 | 建 Diffuser 類別 | 修復師的工作手冊 |
| Step 6 | 訓練模型 | 上課:猜沙子,對答案 |
| Step 7 | 生成圖片 | 畢業考:從純沙子掃出數字 |
| Step 8 | 觀察去噪過程 | 慢動作回放掃沙子 |
| Step 9 | 條件生成 + CFG | 升級版:可以點菜了! |
🚀 立即開始實作
下載 Notebook,在 Jupyter 或 Google Colab 中跑一遍,親手體驗擴散模型從噪聲中生成圖像的魔法。
想深入了解擴散模型的數學原理、架構演進與 Stable Diffusion 實戰?請閱讀我們的擴散模型深度解析。