- McKinsey 估計生成式 AI 可為全球銀行業每年增加 2,000 億至 3,400 億美元價值(約佔營業利潤的 9-15%)[3]——金融業是 AI 商業價值最高的產業之一
- WEF 報告顯示金融業 AI 投資預計在 2027 年達到 970 億美元,84% 的金融機構正在實施或規劃 AI 治理框架[7]——合規不再是選項,而是必要條件
- EBA 調查發現約 40% 的歐盟銀行已使用通用 AI(GPAI),主要用於客服與內部流程優化[9]——採用率快速成長但以低風險場景為主
- 台灣金管會已於 2024 年 6 月發布《金融業運用 AI 指引》,確立 6 大核心原則[2]——台灣金融機構的 AI 導入從此有了明確的合規框架
一、全球金融 AI 監管版圖:三大法規框架
金融業是 AI 監管最嚴格的產業。原因很簡單:AI 在金融業的決策——信用評分、保險定價、投資建議、反洗錢篩選——直接影響個人權益與金融穩定。BIS 金融穩定研究所在其最新報告[5]中指出,雖然 AI 並未引入根本性的「全新」風險,但在治理、模型風險管理與第三方 AI 服務提供商的依賴性上,現有監管框架仍有需要加強的空間。
1.1 歐盟 AI Act——金融業的高風險分類
歐盟《AI Act》(Regulation (EU) 2024/1689)[1]將在 2026 年 8 月 2 日全面適用。對金融業最直接的影響在於其「高風險 AI」分類——Annex III 明確列出以下金融場景屬於高風險:
- 信用評分與信用風險評估——用於評估自然人信用度或信用評分的 AI 系統
- 保險定價與風險評估——用於人壽和健康保險的風險評估與定價
- 詐欺偵測——用於偵測金融詐欺的 AI 系統(特定情境下)
被歸類為高風險的 AI 系統必須遵守嚴格要求:自動生成日誌、風險管理系統、數據治理、技術文件、透明度義務、以及人工監督(Human Oversight)。罰款可達 3,500 萬歐元或全球營收的 7%。
EBA(歐洲銀行管理局)的分析[9]指出,EU AI Act 與現有歐盟銀行業法規之間並無重大矛盾——這對金融機構是好消息,意味著合規工作可以建構在既有法遵框架之上,而非從零開始。但 EBA 同時發現約 40% 的歐盟銀行已使用通用 AI,顯示實際部署已遠超監管的準備進度。
1.2 台灣金管會《金融業運用 AI 指引》
台灣金管會於 2024 年 6 月正式發布《金融業運用人工智慧(AI)指引》[2],建立了 6 大核心原則:
- 治理與問責(Governance & Accountability):建立董事會層級的 AI 監督機制,明確權責歸屬
- 公平與以人為本(Fairness & Human-Centered):避免演算法偏見,確保 AI 決策不歧視特定族群
- 隱私與客戶權益保護(Privacy & Customer Rights):符合《個人資料保護法》,告知客戶 AI 使用情形
- 系統穩健與安全(Robustness & Security):AI 系統的資安防護與營運持續性
- 透明與可解釋(Transparency & Explainability):高影響力決策(如拒絕貸款)須可向客戶解釋
- 永續發展(Sustainable Development):考量 AI 對社會與環境的影響
該指引屬於「行政指導」而非具法律強制力的法規。但對受監管的金融機構而言,金管會的行政指導在實務上具有準法律效力——未遵循者在金融檢查中將面臨關切,也可能影響業務許可的核准。
1.3 美國:SEC 與 AI Washing 執法
美國在金融 AI 監管上採取更偏執法導向的路徑。SEC(美國證券交易委員會)已針對「AI Washing」——即企業誇大 AI 能力以吸引投資人——展開執法行動[14]。SEC 的 2025 年檢查重點明確包含:審查投資顧問將 AI 整合進投資組合管理、交易、行銷與合規的情形。
FSB(金融穩定委員會)的報告[6]更從系統性風險的角度提出四大警示:(一)第三方 AI 服務提供商的集中度風險——若多數金融機構使用同一家 AI 供應商的模型,其失誤將造成系統性連鎖效應;(二)AI 驅動交易策略的同質化可能放大市場波動;(三)AI 系統的資安風險;(四)生成式 AI 可能被用於金融詐欺與市場操縱。
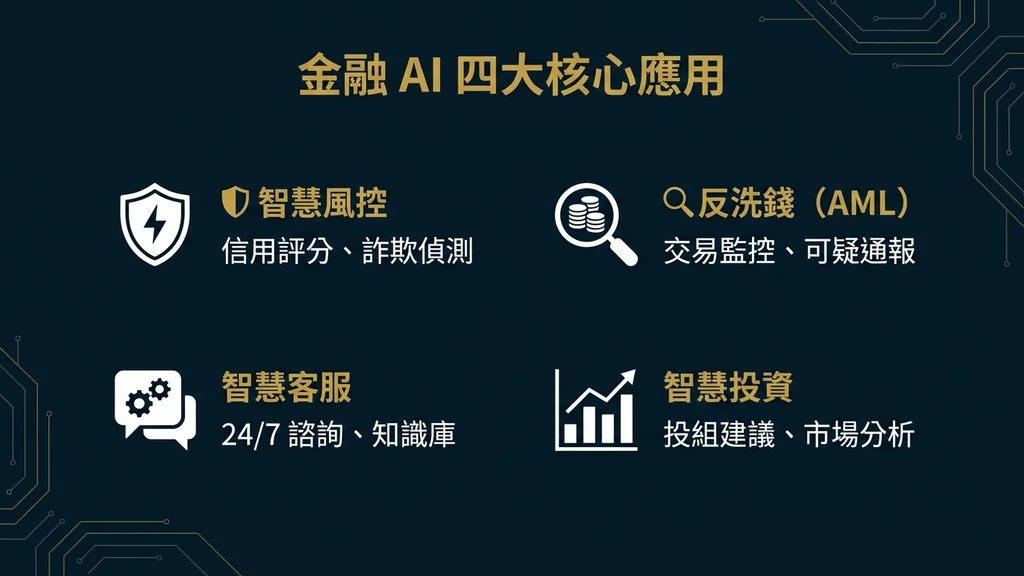
二、高價值場景:金融業 AI 的四大核心應用
McKinsey 的分析[3]指出,生成式 AI 為銀行業帶來的 2,000-3,400 億美元年度價值,主要來自生產力提升。Deloitte 進一步預測[8],AI 工具可在 2028 年前將銀行業軟體投資成本降低 20-40%,每位工程師節省可達 110 萬美元。以下是 ROI 最高且合規挑戰最具代表性的四大場景。
2.1 智慧風控與信用評分
信用評分是 EU AI Act 明確列為「高風險」的 AI 應用[1]。傳統的信用評分模型(如 FICO、台灣聯徵中心評分)基於有限的結構化變數——收入、負債比、還款紀錄。AI 模型可以整合更豐富的數據維度,提升風險預測精度,但同時引入了可解釋性的挑戰。
CFA Institute 的研究[10]指出,不同利害關係人(監管者、風險經理、投資專業人員、開發者、客戶)對 AI 解釋有截然不同的需求——監管者需要「模型為什麼做出這個決策?」的全局解釋,客戶需要「我的申請為什麼被拒絕?」的個案解釋。金融機構在導入 AI 信用評分時,必須同時滿足這兩種解釋需求。
BIS 的 XAI 專文[13]進一步警示:現有的可解釋 AI 技術(如 SHAP、LIME)存在不精確性與不穩定性的根本限制。監管者可能需要在可解釋性與模型效能之間接受一定的取捨——前提是機構提供了充分的替代保障措施。
2.2 反洗錢(AML)與金融犯罪偵測
反洗錢是金融業 AI 投資最積極的場景之一。PwC 的 EMEA AML 調查[11]顯示,97% 的英國金融機構計劃在未來兩年內為 AI 與數位 AML 工具編列預算。然而,障礙同樣顯著:55% 的受訪機構擔心現有 AML 流程的成熟度不足以支撐 AI 導入,52% 對與外部服務提供商共享數據感到憂慮。
傳統的 AML 系統以規則引擎(Rule-Based)為基礎,面臨「高假陽性率」的根本問題——業界估計假陽性率可達 90-95%,意味著合規團隊花費大量時間調查最終被確認為正常的交易。AI 驅動的 AML 系統透過行為分析與異常偵測,可將假陽性率降低 50-70%,同時提升真實可疑交易的偵測率。
FSB 的報告[6]提醒金融機構注意一個新興風險:生成式 AI 正在被用於製造更精緻的金融詐欺——包括深度偽造(Deepfake)身分驗證、AI 生成的釣魚郵件、以及利用 AI 規避 AML 偵測的手法。這意味著 AML 團隊需要同時升級防禦端(導入 AI 偵測)與攻擊端(理解 AI 被惡意利用的方式)。
2.3 智慧客服與理財助手
客戶服務是金融業 AI 導入門檻最低、風險最可控的場景。EBA 的調查[9]顯示,約 40% 的歐盟銀行已使用通用 AI,主要用於客服與內部流程優化——這兩個場景的 AI 分類屬於「低風險」或「有限風險」,合規負擔遠低於信用評分等高風險場景。
然而,「低風險」不代表「零風險」。金管會的 AI 指引[2]在「公平與以人為本」原則中要求:AI 客服若涉及金融產品推薦,必須避免演算法偏見導致的不當推介(例如:向不適合高風險產品的客戶推薦高風險基金)。此外,若 AI 客服的回應可能被視為「投資建議」,則可能觸發更嚴格的適合性評估(Suitability)義務。
2.4 保險定價與理賠自動化
保險業是 AI 合規挑戰最獨特的金融子產業。EIOPA(歐洲保險與職業退休金管理局)的報告顯示,50% 的產險保險商與 24% 的壽險保險商已在保險價值鏈中使用 AI——從核保、定價、理賠處理到詐欺偵測。
Deloitte 的預測[8]指出,AI 驅動的理賠分析可在 2032 年前為保險業節省 800 億至 1,600 億美元。但保險定價的 AI 模型面臨特殊的合規挑戰:EU AI Act 將人壽和健康保險的 AI 風險評估列為「高風險」[1],這意味著保險公司必須確保 AI 定價模型不會基於性別、種族、疾病史等受保護特徵進行歧視性定價。
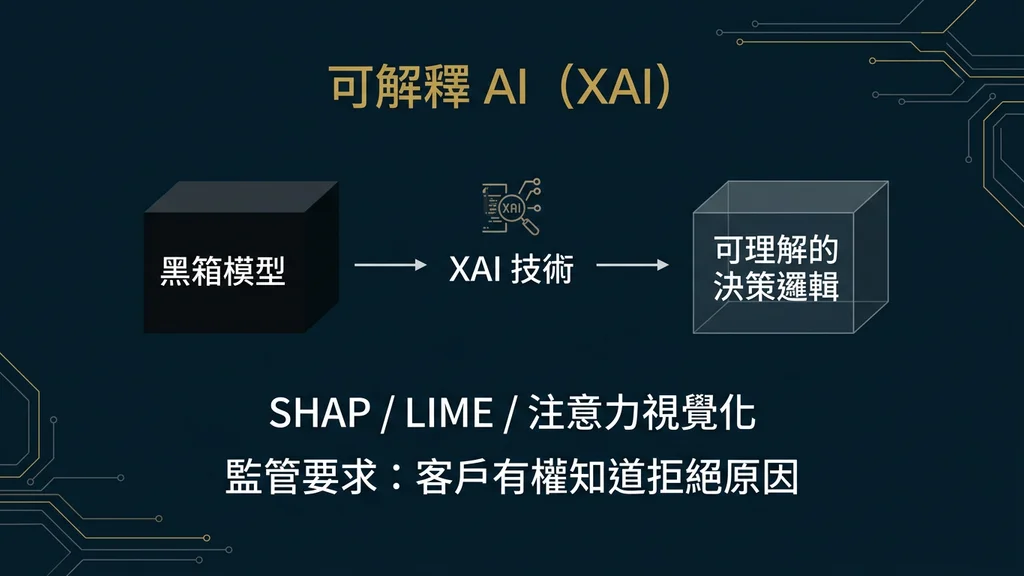
三、可解釋 AI(XAI):金融 AI 合規的核心技術挑戰
在金融業 AI 的所有合規要求中,「可解釋性」(Explainability)是技術難度最高、也最常被低估的一項。BIS 的專文[13]深入分析了這一挑戰:
技術限制:目前最廣泛使用的 XAI 技術——SHAP(SHapley Additive exPlanations)與 LIME(Local Interpretable Model-agnostic Explanations)——存在根本性的限制。SHAP 在特徵交互作用強烈的場景中可能產生誤導性的歸因,LIME 的局部解釋在不同輸入下可能不穩定。對金融業而言,這意味著依賴單一 XAI 方法是不夠的。
「效能 vs. 可解釋性」的取捨:深度學習模型通常比可解釋性強的線性模型或決策樹具有更高的預測精度。監管者是否應該要求金融機構犧牲一定的模型效能來換取更高的可解釋性?BIS 的建議是:允許在適當的保障措施下進行取捨,但監管者必須提升自身的 AI 評估能力來判斷保障措施是否充分。
CFA Institute 的研究[10]提出了一個實務框架:針對不同利害關係人設計不同層次的解釋——全局解釋(Global Explanation)給監管者、局部解釋(Local Explanation)給客戶、技術解釋(Technical Explanation)給模型驗證團隊。該報告也呼籲建立全球性的 AI 解釋品質衡量標準。
NIST AI RMF[4]的「透明性」(Transparency)原則提供了額外的指引:AI 系統的透明性不僅是「能解釋模型」,更包括「誰設計了模型、用什麼數據訓練、模型的已知限制是什麼」。金融機構應將 XAI 視為一個涵蓋模型全生命週期的持續性流程,而非事後補充的技術附件。
四、資料治理與模型治理:金融 AI 的兩大治理支柱
4.1 資料治理
FSB 的報告[6]將「數據品質與治理」列為 AI 帶給金融穩定的四大風險之一。在金融業,數據治理的挑戰尤其嚴峻:
- 數據品質:AI 模型的輸出品質取決於輸入數據的品質。歷史貸款數據若包含過去歧視性放貸政策的殘留(如對特定地區的系統性拒貸),AI 模型將學習並放大這些偏見
- 隱私合規:金管會 AI 指引[2]要求金融機構確保 AI 使用符合《個人資料保護法》,包括取得適當同意、最小化資料蒐集、以及確保跨境資料傳輸的合法性
- 第三方數據風險:BIS[5]特別指出,金融機構越來越依賴第三方 AI 服務提供商的數據與模型,但對這些外部資源的品質與偏見往往缺乏有效的控制機制
4.2 模型治理
WEF 的報告[7]顯示,84% 的金融機構正在實施或規劃 AI 治理框架。有效的模型治理應包含:
模型風險管理(MRM):建立獨立的模型驗證團隊,對 AI 模型進行上線前測試(驗證準確性、穩定性、公平性)與上線後監控(偵測效能衰退與概念漂移)。
模型清冊(Model Inventory):維護組織內所有 AI 模型的清冊——包括模型用途、風險等級、訓練數據來源、負責人、上次驗證日期。EU AI Act[1]要求高風險 AI 系統必須維護自動生成日誌,模型清冊是滿足此要求的基礎。
變更管理:模型更新(重新訓練、參數調整、數據來源變更)需經過正式的審核流程。HBR 的研究[12]指出,負責任的 AI 實踐不僅是合規成本,更能保護企業的底線——消費者研究顯示,負責任 AI 實踐可產生顯著的經濟回報。
五、台灣金融業 AI 導入的特殊考量
5.1 監管環境
台灣金融業的 AI 監管環境有幾個值得注意的特點。首先,金管會的《AI 指引》[2]是行政指導而非法規——但台灣金融機構在金管會的監管密度下,實務上視其為準法規。其次,台灣是全球最早建立金融科技監理沙盒專法(《金融科技發展與創新實驗條例》,2017 年 12 月)的國家,顯示監管者對金融創新的開放態度。
2025 年 12 月通過的《人工智慧基本法》進一步為金融 AI 提供了上位法律框架——7 大治理原則(永續發展、人類自主、隱私保護、資安、透明、公平、問責)與金管會 AI 指引的 6 大原則高度一致,減少了法規衝突的風險。
5.2 導入策略建議
基於上述監管環境與國際趨勢,我們為台灣金融機構建議以下導入策略:
(1) Phase 1 — 低風險場景先行:智慧客服、內部文件處理、會議紀錄摘要——這些屬於 EU AI Act 的「有限風險」或「低風險」分類,合規負擔最輕
(2) Phase 2 — 中風險場景擴展:AML 交易監控輔助、保險理賠初步篩選、行銷客群分析——需建立基本的模型治理框架
(3) Phase 3 — 高風險場景慎入:信用評分輔助、投資建議系統、保險定價模型——需完整的 XAI 機制、模型驗證與合規文件
建立「AI 合規委員會」:由法遵長(CCO)、資訊長(CIO)與業務主管共同組成,負責 AI 專案的風險分級、上線審核與持續監控。金管會 AI 指引[2]要求的「治理與問責」原則,在組織層面即體現為這樣的跨部門治理結構。
投資可解釋性基礎設施:不要等到監管要求時才補做 XAI。BIS[13]的建議是趁早建立多層次解釋能力——全局解釋、局部解釋、技術解釋——作為所有 AI 模型上線的標準流程。
關注第三方風險:BIS[5]與 FSB[6]均將第三方 AI 服務提供商的集中度風險列為重點關注。台灣金融機構在選擇 AI 供應商時,應評估供應商鎖定風險(Vendor Lock-in)、數據主權、以及模型可移植性。
六、如何選擇金融業 AI 供應商
金融業的 AI 供應商選擇維度比其他產業更為嚴格:
金融監管理解:供應商是否理解金管會 AI 指引、EU AI Act 的高風險分類要求、以及 AML 相關法規?純技術型 AI 供應商可能在模型效能上表現優異,但在合規文件、模型驗證報告與審計軌跡上經常缺乏準備。
XAI 能力:是否具備多層次可解釋性技術?如本文所述,BIS[13]已指出單一 XAI 方法的不足——供應商應能提供 SHAP、LIME、Attention 可視化等多種解釋方法的組合。
資安與合規認證:是否通過 ISO 27001 / 27701 認證?是否具備處理金融機密資料的資安層級?能否在地端部署以確保資料不外洩?
模型治理支援:是否提供模型清冊、效能監控、概念漂移偵測、自動化合規報告等治理工具?NIST AI RMF[4]的四大功能(Govern、Map、Measure、Manage)可作為評估供應商治理能力的參考框架。
金融業實績:是否有銀行、保險、證券等金融機構的 AI 導入案例?是否理解金融業特有的挑戰——如多層級簽核、金檢準備、營運持續性要求?
七、結語:合規不是障礙,而是護城河
金融業 AI 的監管密度確實高於其他產業——EU AI Act 的高風險分類[1]、金管會的 6 大原則[2]、BIS 與 FSB 的金融穩定警示[5][6]。但 HBR 的研究[12]提供了一個重要的翻轉視角:負責任的 AI 實踐不是成本,而是競爭優勢——消費者信任、監管信任與市場信任,都是 AI 時代的稀缺資源。
WEF 的數據[7]顯示 84% 的金融機構正在建立 AI 治理框架。McKinsey 估計銀行業年度 AI 價值達 2,000-3,400 億美元[3]。問題不是「金融業該不該導入 AI」,而是「如何在合規框架下最大化 AI 的商業價值」。
超智諮詢的團隊結合深度 AI 技術能力與金融監管理解,提供從合規評估、場景篩選、XAI 實作、模型治理到系統上線的完整服務。無論你是正在規劃 AI 策略的金融業 CTO、建立合規框架的法遵主管,還是推動數位金融創新的業務負責人——我們能為你提供從策略到落地的全方位支援。
簡報投影片